library(tidyverse)
library(rvest)
url <- "https://www.nhmrc.gov.au/funding/outcomes-and-data-research/research-funding-statistics-and-data"
data <- read_html(url) |>
rvest::html_table() |>
_[[3]]Stakket barchart
Og lidt af udfordringerne med den type plots
R
Visualisering
Det er ikke en supergod måde at visualisere data på. Godt nok giver den en ide om fordelingen af bidrag til et samlet heles udvikling. Men der er detaljer i grafen, der gør det vanskeligere at tolke det.
Men lad os lave et.
Til en start skal vi have noget data. Jeg har fundet denne side https://www.nhmrc.gov.au/funding/outcomes-and-data-research/research-funding-statistics-and-data fra de australske sundhedsmyndigheder. Der er tre tabeller, og den sidste viser hvor mange penge de bruger på forskning der er målrettet forskellige demografiske grupper.
Lad os begynde med at få fingre i de data:
Og så har vi data!
head(data)# A tibble: 6 × 11
Population `2015$ million` `2016$ million` `2017$ million` `2018$ million`
<chr> <dbl> <dbl> <dbl> <dbl>
1 Aboriginal an… 55.8 51.7 49.6 50
2 Adolescent He… 26.2 20.3 18.9 20.2
3 Aged Health 40.7 36.2 36.6 39.5
4 Child Health 112. 98.3 96.7 103.
5 Maternal Heal… 60 47.2 45.4 46
6 Men’s Health 20.5 17 17 18.6
# ℹ 6 more variables: `2019$ million` <dbl>, `2020$ million` <dbl>,
# `2021$ million` <dbl>, `2022$ million` <dbl>, `2023$ million` <dbl>,
# `2024$ million` <dbl>Det er ikke specielt tidy, så lad os fikse det.
data <- data |>
pivot_longer(-1) |> # pivoter tabellen
mutate(År = str_extract(name, "\\d{4}"), # ekstraher årstal
År = as.numeric(År)) |> # coerce til numerisk
select(-name) # deselect overflødig kolonne
head(data)# A tibble: 6 × 3
Population value År
<chr> <dbl> <dbl>
1 Aboriginal and Torres Strait Islander Health 55.8 2015
2 Aboriginal and Torres Strait Islander Health 51.7 2016
3 Aboriginal and Torres Strait Islander Health 49.6 2017
4 Aboriginal and Torres Strait Islander Health 50 2018
5 Aboriginal and Torres Strait Islander Health 54.4 2019
6 Aboriginal and Torres Strait Islander Health 57.2 2020Og så er vi sådan set klar til at plotte:
data |>
ggplot(aes(x = År, y = value, fill = Population)) +
geom_area()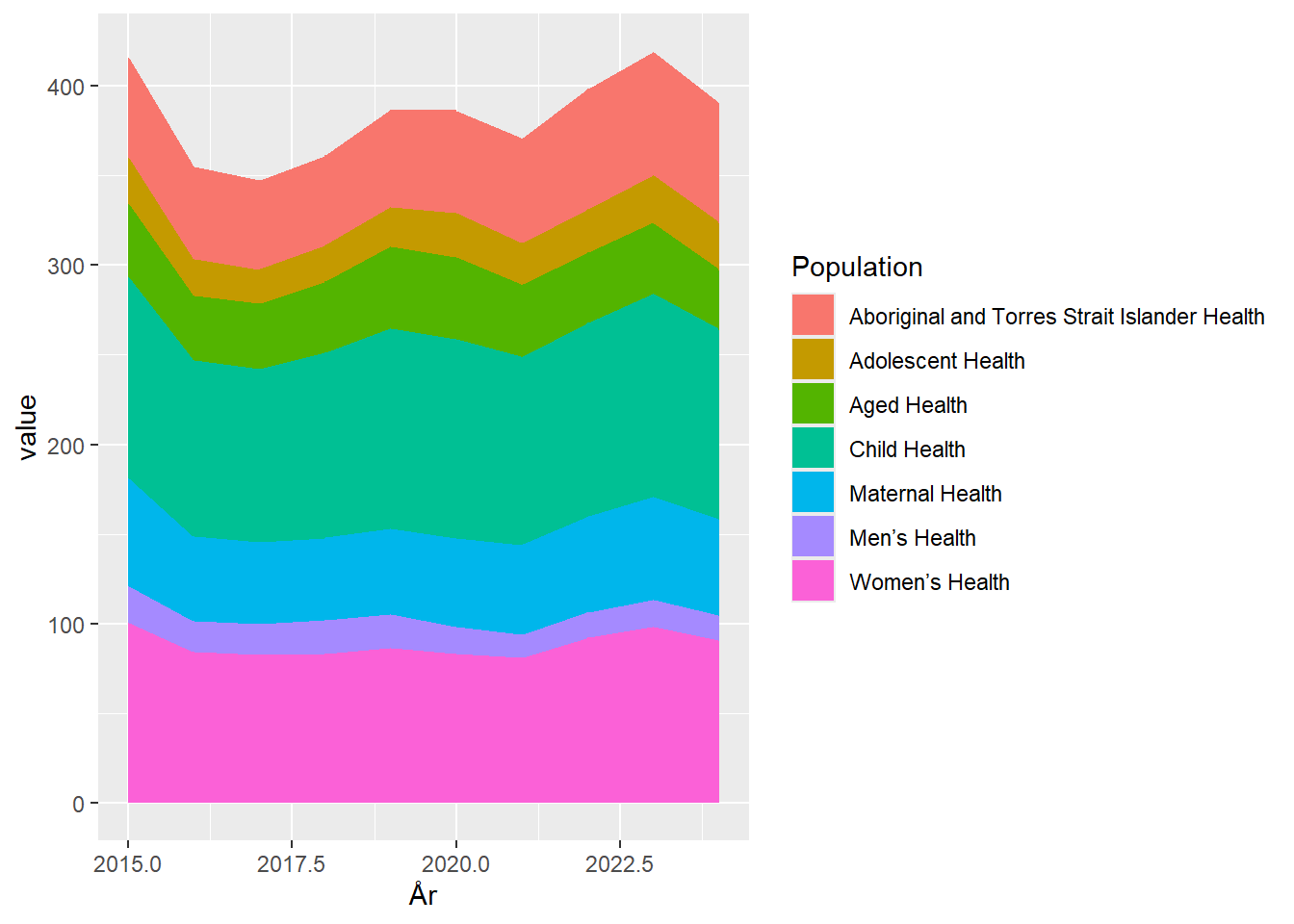
Vupti. Vi starter med at plotte hvor mange AUS$ der bruges på forskning i kvinders sundhed. Oven på det plotter vi så hvor mange aud der bruges på forskning i mænds sundhed, og så fortsætter vi opad. Tallene er som nævnt i dollar, og det fremgår ikke om de er korrigeret for inflation.
Fordelen ved at stakke de absolutte tal er at vi får det samlede beløb med det samme. Ulempen er at det er vanskeligt at se hvilken andel hver enkel demografisk gruppe får af den samlede sum. Selvom det jo er meget tydeligt at kvinder er voldsomt underprioriteret.
Et alternativ er at plotte de relative værdier, altså den procentvise fordeling.
Det gør vi ret let, det er blot et ekstra argument til geom_area:
data |>
ggplot(aes(x = År, y = value, fill = Population)) +
geom_area(position = "fill")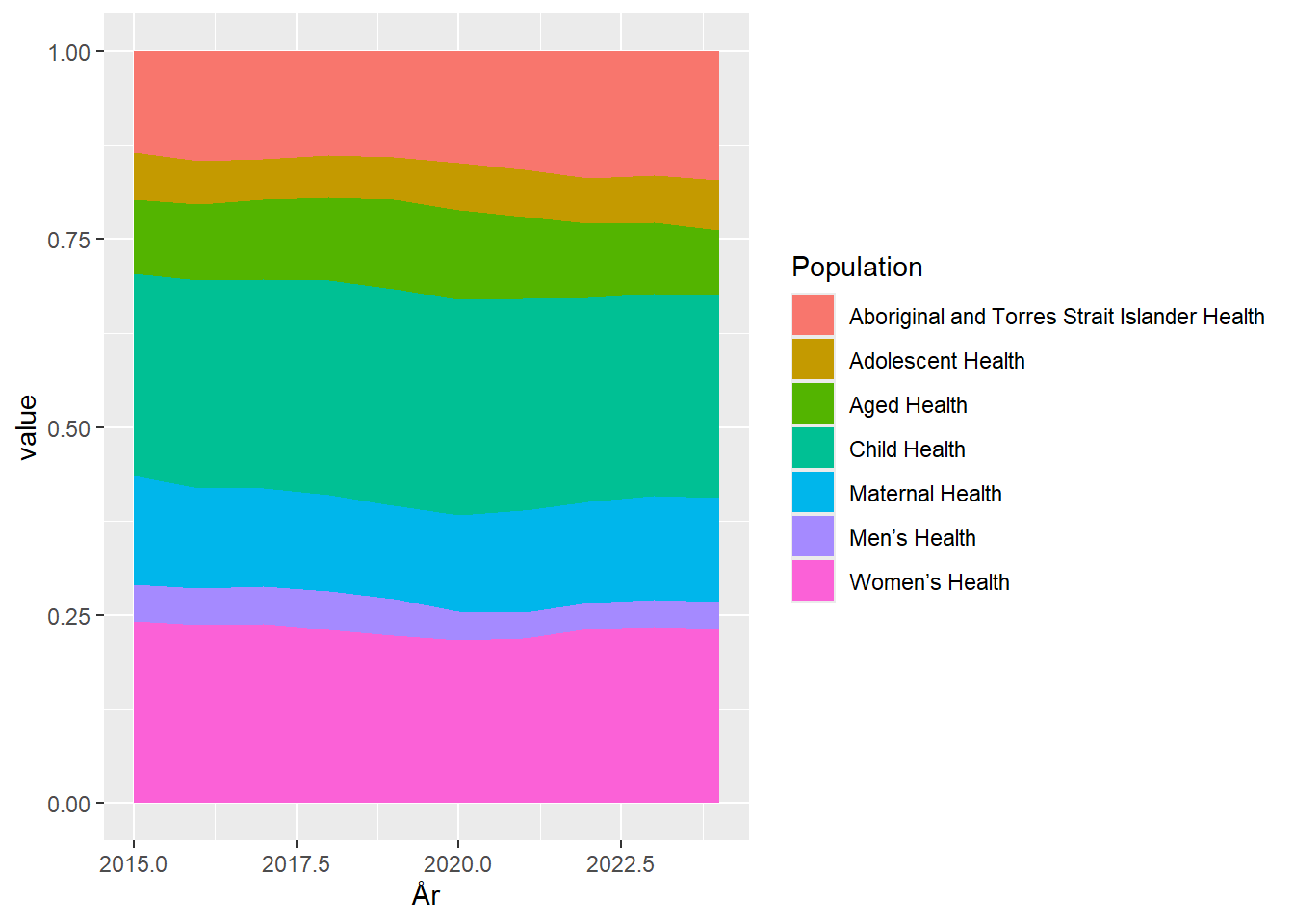
Nu bliver det lidt lettere at se hvor stor en andel af de samlede forskningsbevillinger der går til hver gruppe - stiger eller falder de? Og det bliver tydeligt at selv hvis vi lægger “Maternal Health” sammen med “Women’s Health” er det under 50% af bevillingerne der går specifikt til kvinder. Men det er vanskeligt faktisk at aflæse at det i 2024 kun var 37% der gik til forskning i kvinders sundhed, fordi “Men’s Health” ligger mellem de to kategorier, og får den samlede værdi til at se 3,5% større ud.
Det kan vi fikse ved at justere på rækkefølgen af kategorierne. Som sædvanligt når vi skal styre rækkefølger i ggplot, skal vi have fat i faktorer. Vi mutater “Population” til at være en kategorisk variabel, og ændrer rækkefølgen. En særlig udfordring er at fct_relevel skal have en numerisk værdi i after argumentet. Så det piller vi ud semi-manuelt:
data |>
mutate(Population = factor(Population)) |>
mutate(Population = fct_relevel(Population,
"Men’s Health",
after = match("Maternal Health", levels(Population)) - 1 )) |>
ggplot(aes(x = År, y = value, fill = Population)) +
geom_area(position = "fill")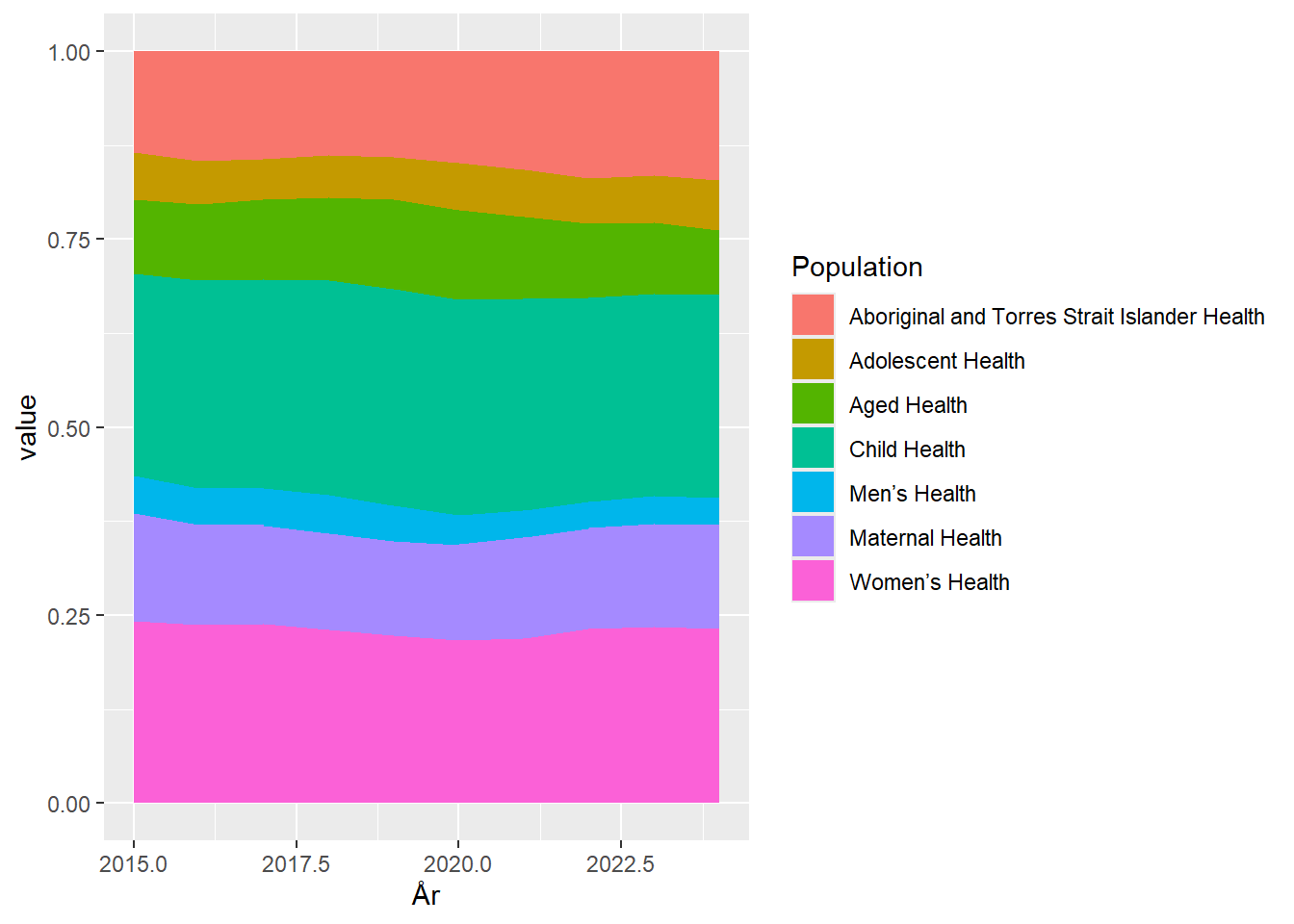
Vupti. De 3.5% der bruges på forskning i mænds sundhed ligger ikke længere mellem “Maternal Health”, og “Women’s Health”, og det er langt tydeligere at de ca 37% af bevillingerne der bruges på forskning i kvinders sundhed udtryk for en voldsom underprioritering af kvinder.
Det ændrer ikke på at det er vanskeligt at aflæse på grafen hvor stor en andel der bruges på “Aged Health”, og en tabel vil ofte være at foretrække hvis man faktisk er interesseret i udviklingen. Det er næppe et tilfælde at de oprindelige data netop præsenteres som en tabel.
Tricket med at bruge matchs og levels til at få den numeriske værdi der skal bruges når rækkefølgen skal ændres er ret fikst, hvis jeg selv skal sige det.
Så mangler der blot at få smukkeseret plottet. Til en start kunne man fjerne den grå baggrund, der er inderligt overflødig her. Breaks på X-aksen bør gå på hele år, og når vi summerer til 100% vil de fleste sætte pris på at Y-aksen går fra 0 til 100. En titel og en caption vil også være fint, men det overlades til den interesserede studerende.